
BrainX Waves: The Newsletter of BrainX Community
November 2024: Issue 5

Learn
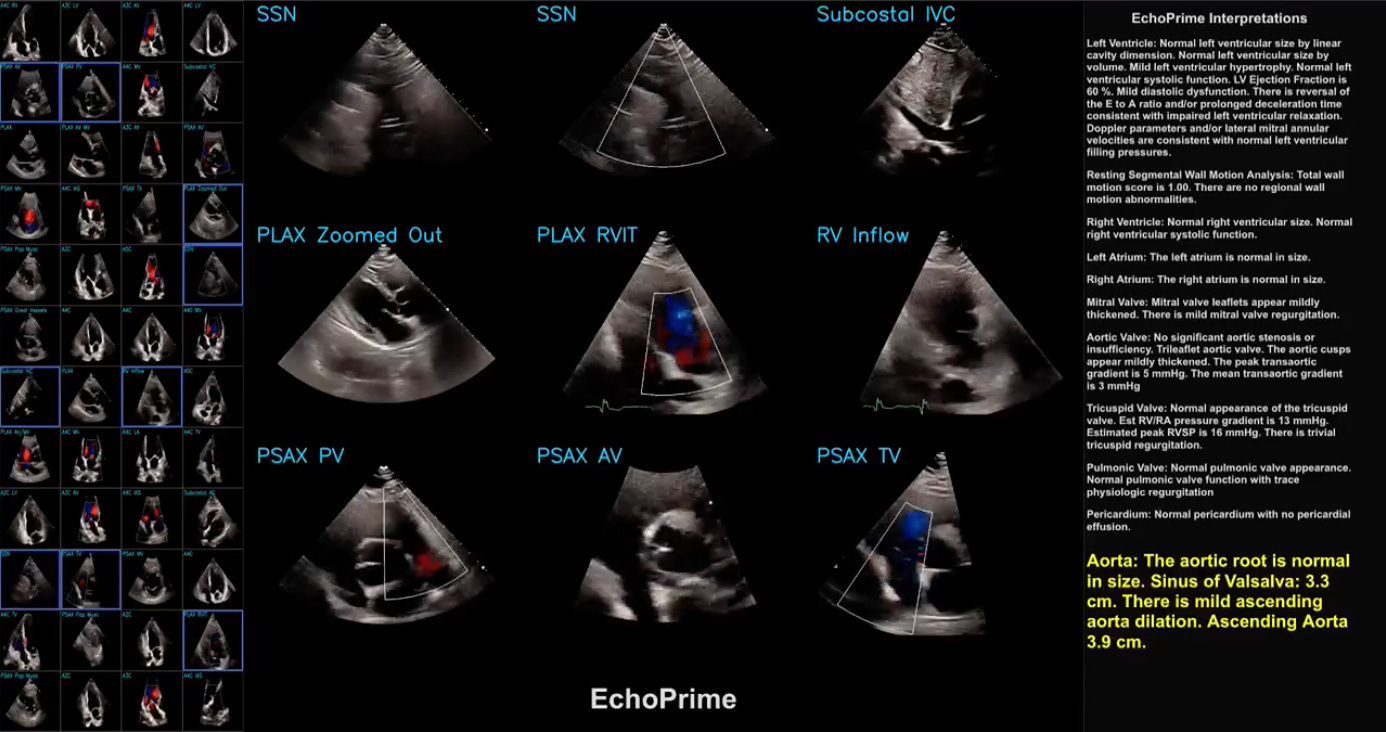
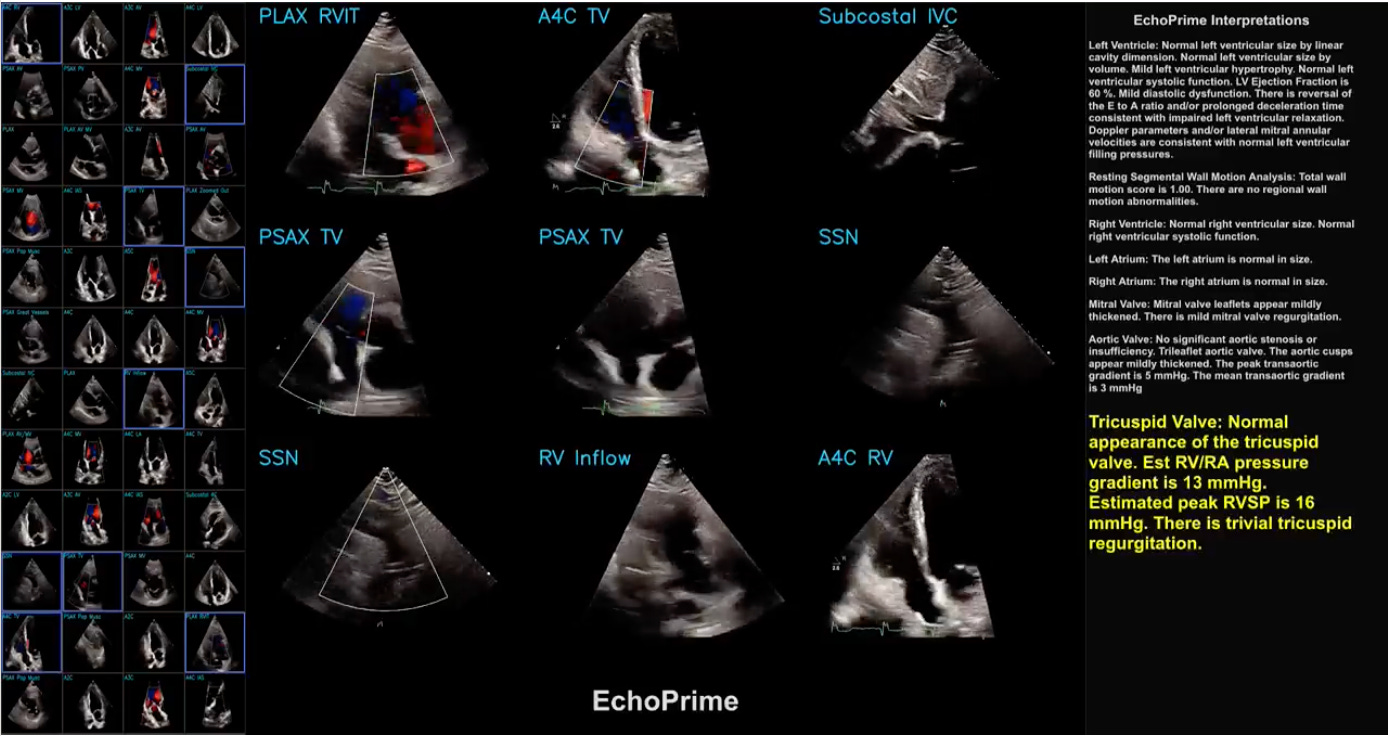
EchoPrime is a multi-view, view-informed, video-based vision-language foundation model trained on over 12 million video-report pairs.
EchoPrime uses contrastive learning to train a unified embedding model for all standard views in a comprehensive echocardiogram study with a representation of both rare and common diseases and diagnoses. EchoPrime then utilises view-classification and a view-informed anatomic attention model to weight video-specific interpretations that accurately maps the relationship between echocardiographic views and anatomical structures.
With retrieval-augmented interpretation, EchoPrime integrates information from all echocardiogram videos in a comprehensive study and performs holistic, comprehensive clinical echocardiography interpretation. In datasets from two independent healthcare systems, EchoPrime achieves state-of-the-art performance on 23 diverse benchmarks of cardiac form and function, surpassing the performance of both task-specific approaches and prior foundation models.
Following rigorous clinical evaluation, EchoPrime can assist physicians in the automated preliminary assessment of comprehensive echocardiography.
Connect
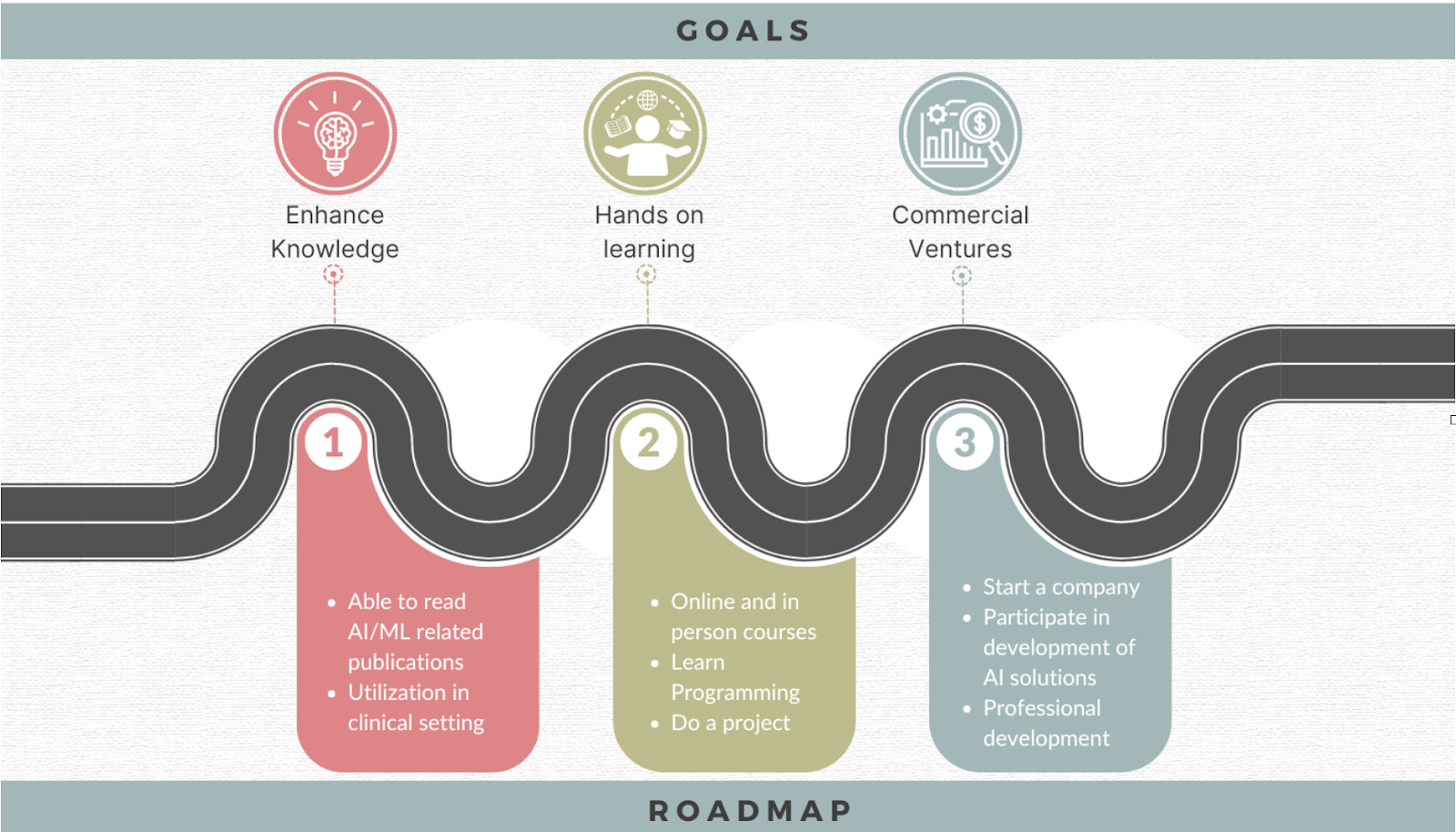
This BrainX Community Live! event featured Drs. Amit Kumar Dey, Sameer Shaikh, Avneesh Khare, & Anirban Bhattacharyya to discuss the most commonly asked question by clinicians: “How do I get started with AI?" The panelists discussed the growing importance of AI in healthcare and the need for clinician engagement. They discussed the key topics of defining goals for oneself, identifying personalised resources for learning, which courses to take, if programming is needed, and how to measure success.
Related publication: Mathur P, Arshad H, Grasfield R, et al. (October 27, 2024) Navigating AI: A Quick Start Guide for Healthcare Professionals. Cureus 16(10): e72501.
Join our upcoming BrainX Community Live! December 11, 2024, 11 am - noon ET event:
BrainX Community Live! December 2024: Foundation models in Cardiology - Automating Echocardiography with Echoprime
Register here: https://us02web.zoom.us/meeting/register/tZMkde-urjwsHdVpEHWmdyWIEBIzd8SiRePE#/registration
Speakers: Milos Vukadnovic, PhD Candidate at UCLA; I-Min Chiu, MD, PhD
Datasets
This information retrieval test collection contains * 204,855 publicly available clinical trials crawled from ClinicalTrials.gov. * 60 topics comprised of three types: patient case descriptions, patient case summaries, and assessor-provided ad-hoc queries, totalling an average of 10.2 queries per topic. * 4,000 assessor-provided relevance assessments for topic and trial pairs.
TREC Biomedical Tracks datasets
This site hosts the information for three of the five major medical track series that have run at the Text REtrieval Conference (TREC), with links to the other two major track series below. These tracks have sought to provide benchmark datasets and evaluate information retrieval systems focused on many of biomedicine's most important information access problems.
BraTS-Africa (Brain Tumor Segmentation MRI dataset)
The dataset is a collection of retrospective preoperative brain magnetic resonance imaging (MRI) scans, clinically acquired from six diagnostic centres in Nigeria.
The scans are from 146 patients who have brain MRIs indicating central nervous system neoplasms, diffuse glioma, low-grade glioma, or glioblastoma/high-grade glioma. The brain scans were multiparametric MR images (mpMRI), specifically T1, T1 CE, T2, and T2 FLAIR, acquired on 1.5T MRI between January 2010 and December 2022. The expert-annotated tumour sub-regions for each of the 146 cases are provided along with metadata (csv file) of study location and scanner type, where available.
The MTS-Dialog dataset is a new collection of 1.7k short doctor-patient conversations and corresponding summaries (section headers and contents). The training set consists of 1,201 pairs of conversations and associated summaries. The validation set consists of 100 pairs of conversations and their summaries. MTS-Dialog includes 2 test sets; each test set consists of 200 conversations and associated section headers and contents.
The augmented dataset consists of 3.6k pairs of medical conversations and associated summaries created from the original 1.2k training pairs via back-translation using two languages, French and Spanish, as described in the paper.
Aci-bench: Ambient Clinical Intelligence Dataset
The corpus, created from domain experts, is designed to model three variations of model-assisted clinical note generation from doctor-patient conversations. These include conversations with (a) calls to a virtual assistant (e.g., required use of wake words or prefabricated, canned phrases), (b) unconstrained directions or discussions with a scribe, and (c) natural conversations between a doctor and patient. Contains 1342 samples.
Podcast
In this episode, we feature Dr. Kamal Maheshwari, MD, MPH, FASA. Dr. Maheshwari is a distinguished anaesthesiologist with extensive experience in clinical practice, research, and innovation. He is the founder of Roojh Health, an organisation dedicated to enhancing healthcare in developing countries. The primary mission of Roojh Health is to empower doctors and patients with high-quality information for better decision-making. He is also the founding partner of BrainX, LLC.
We discuss his journey, all the way from medical school in India to becoming a prominent researcher in healthcare. He talks about his inspirational work towards democratising digital health, AI entrepreneurship, and a transformational vision for the future of healthcare.
Conferences
Additional BXC-featured publications
Generative AI/LLM
Matching patients to clinical trials with large language models
MedMobile: A mobile-sized language model with expert-level clinical capabilities
Large Language Model Influence on Diagnostic Reasoning: A Randomized Clinical Trial
Book/General
Join and follow the BrainX community!
Webpage: https://brainxai.org/
Newsletter: https://brainxai.substack.com/subscribe
LinkedIn: https://www.linkedin.com/groups/13599549/
Youtube: https://www.youtube.com/channel/UCua5EiLL6I29hpNrJsdv1rg